이전 포스팅에서 이상치의 정의와 이상치를 확인하는 방법에 대해 알아보았습니다. 이번 포스팅에서는 이상치 처리 방법과 이상치 처리 결과를 실습을 통해 알아보겠습니다.
실습 준비
gpa 파일 다운로드
google drive -> 내 드라이브 -> Data -> 업로드
colab 실행
# 구글 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive')
# 판다스 라이브러리
import pandas as pd
# seaborn 라이브러리
import seaborn as sns
# numpy 라이브러리
import numpy as np
# gpa(grade point average) 평점 데이터 불러오기
gpa = pd.read_csv('/content/drive/MyDrive/Data/gpa.csv')
# student_id로 인덱스 만들기
gpa = gpa.set_index('student_id')
# 5줄만 출력하기
gpa.head()

# 데이터 정보 및 결측치 유무 확인
gpa.info()
<class 'pandas.core.frame.DataFrame'>
Index: 50 entries, 1 to 50
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 credit 50 non-null int64
1 GPA 50 non-null float64
dtypes: float64(1), int64(1)
memory usage: 1.2 KB
# 데이터프레임 크기 확인하기
gpa.shape
(50, 2)
# 데이터 요약통계량 확인하기
gpa.describe()

이상치 처리
이상치 처리는 데이터 분석 과정에서 중요한 단계로, 이상치를 어떻게 다루느냐에 따라 분석 결과에 큰 영향을 미칠 수 있습니다. 이상치를 처리하는 방법에는 크게 3가지가 있는데, 데이터의 특성과 분석 목표에 따라 적절한 방법을 선택해야 합니다.
이상치 처리 방법
이상치 무시하기
처음부터 이게 무슨 소리냐?하고 의아하실 수 있는데, 특정 분석에서 이상치가 크게 영향을 미치지 않을 경우 이상치를 그대로 두고 분석을 진행할 수도 있습니다. 또는 이상치라고 생각되는 데이터가 사실은 정상적으로 수집된 데이터일 가능성도 존재합니다. 이 방법은 데이터가 부족한 경우나 이상치가 자연스러운 현상일 때 사용할 수 있습니다.
이상치를 다른값으로 대체하기
이상치를 평균, 중앙값, 상한치, 하한치 또는 다른 논리적인 값으로 대체하는 방법입니다. 이는 이상치가 분석 결과에 중요한 영향을 미칠 때 유용합니다.
이상치 배제하기
이상치를 완전히 제거하는 방법입니다. 이는 데이터가 크고, 이상치가 적은 경우에 유용합니다. 하지만 중요한 정보를 잃을 수도 있으므로 주의해야 합니다. 크게 두 가지 방법이 있는데, 첫 번째 방법을 소개하기 전에 NumPy 라이브러리에 대해 간략하게 알아보겠습니다.
NumPy(넘파이)
NumPy는 Python에서 수치 계산을 위한 핵심 라이브러리로, 과학적 계산과 데이터 분석에 널리 사용됩니다. 이 라이브러리는 다차원 배열 객체와 함께 다양한 수학 함수 및 연산을 제공합니다. NumPy는 특히 대규모 데이터 처리에 효율적이며, 파이썬의 다른 데이터 과학 라이브러리(ex: Pandas, Matplotlib, Scikit-learn)와 잘 통합됩니다.
1. 이상치를 결측치로 만들어 제거하기
박스 플룻 그리기
# 박스플롯을 통해 credit 이상치 확인하기
sns.boxplot(gpa['credit'])

이상치가 2개 있는 것을 확인할 수 있습니다.
이상치 기준 만들기(공통 작업)
# 1사분위수 구하기
Q1 = gpa['credit'].quantile(0.25)
# 3사분위수 구하기
Q3 = gpa['credit'].quantile(0.75)
# IQR 구하기
IQR = Q3 - Q1
# 하한선 구하기
lower_line = Q1 - 1.5 * IQR
# 상한선 구하기
upper_line = Q3 + 1.5 * IQR
# 이상치 구하기
outlier = gpa[(gpa['credit'] < lower_line) | (gpa['credit'] > upper_line)]
outlier

이상치 기준을 정하여 이상치 데이터만 따로 출력하였습니다. (실제로 9학점과 10학점을 들었을 가능성이 있지만, 현재 데이터는 학습을 위한 임의의 데이터로 지금은 통계적 의미에서 이상치로 간주합니다.)
이상치 결측 처리하기
# 이상치를 NaN으로 바꾸기
gpa['credit'] = np.where((gpa['credit'] < lower_line) | (gpa['credit'] > upper_line), np.nan, gpa['credit'])
# 결측치 빈도 확인
gpa['credit'].isna().sum()
2
결측치 제거하기
# 결측치 제거하기
gpa = gpa.dropna(subset='credit')
# 결측치가 제거 확인하기
gpa['credit'].isna().sum()
0
2. 불린인덱싱으로 필요한 부분만 출력하기
앞에서 만든 이상치 기준을 활용하여 정상 범위 데이터를 인덱싱할 수 있습니다. 부등호 방향을 반대로만 바꾸면 됩니다!
# 불린 인덱싱을 통해 이상치를 제외한 부분만 출력하기
gpa[(gpa['credit'] >= lower_line) & (gpa['credit'] <= upper_line)]
출력생략
GPA 이상치도 같은 방식으로 처리하면 됩니다. 먼저 코드를 작성해보시고 답안을 보시면 좋을 것 같습니다.
# 박스플롯을 통해 GPA 이상치 확인하기
sns.boxplot(gpa['GPA'])
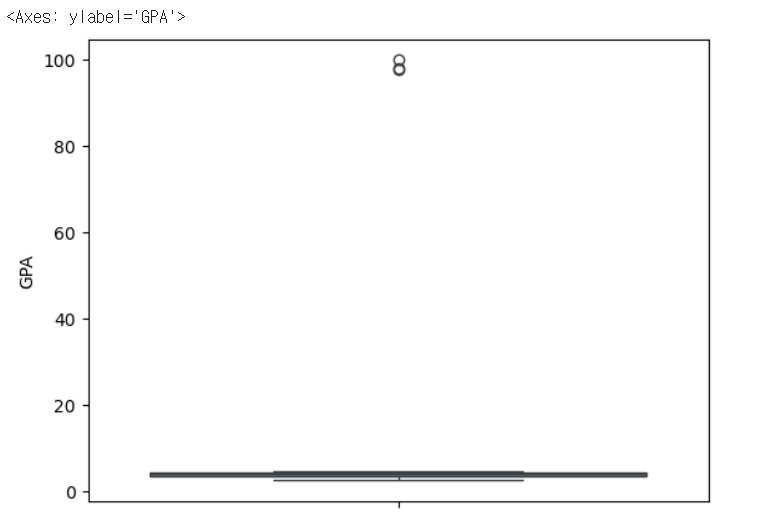
# 1사분위수 구하기
Q1 = gpa['GPA'].quantile(0.25)
# 3사분위수 구하기
Q3 = gpa['GPA'].quantile(0.75)
# IQR 구하기
IQR = Q3 - Q1
# 하한선 구하기
lower_line = Q1 - 1.5 * IQR
# 상한선 구하기
upper_line = Q3 + 1.5 * IQR
# 이상치 구하기
outlier = gpa[(gpa['GPA'] < lower_line) | (gpa['GPA'] > upper_line)]
outlier

# 이상치를 NaN으로 바꾸기
gpa['GPA'] = np.where((gpa['GPA'] < lower_line) | (gpa['GPA'] > upper_line), np.nan, gpa['GPA'])
# 결측치 빈도 확인
gpa['GPA'].isna().sum()
3
# 결측치 제거하기
gpa = gpa.dropna(subset='GPA')
# 결측치가 제거 확인하기
gpa['GPA'].isna().sum()
0
이번 포스팅에서 이상치를 처리하는 3가지 방법에 대해서 알아보았는데요, 데이터 분석에는 정답이 없다고 해도 과언이 아닙니다. 데이터의 특성 상황에 따라 적합한 방법을 찾아 사용하는 것을 추천합니다.
'파이썬을 활용한 데이터 분석 입문' 카테고리의 다른 글
| [Python]데이터 전처리 - 파생변수 만들기 (0) | 2024.08.14 |
|---|---|
| [Python]데이터 전처리 - 데이터 정렬과 메소드 체이닝 (0) | 2024.08.12 |
| [Python]데이터 전처리 - 데이터 정제(2) 이상치 확인하기 (0) | 2024.08.10 |
| [Python]데이터 전처리 - 데이터 정제(1) 결측치 처리 (0) | 2024.08.09 |
| [Python]데이터 전처리 - 데이터 인덱싱(2) 불린 인덱싱과 query (0) | 2024.08.08 |