데이터 분석을 하다 보면 여러 데이터프레임을 합쳐서 분석해야 하는 경우가 자주 발생합니다. 이번 포스팅에서는 Pandas의 주요 데이터 합치기 메소드인 concat, merge, join과 이들 메소드에서 자주 사용되는 주요 파라미터 옵션들에 대해 알아보겠습니다.
concat 메소드
concat 메소드는 여러 데이터프레임을 단순히 연결(concatenate) 할 때 사용됩니다. 축(axis)을 기준으로 데이터프레임을 이어 붙이는 방식입니다.
import pandas as pd
# 샘플 데이터프레임 생성
df1 = pd.DataFrame({'A': ['A0', 'A1', 'A2'],
'B': ['B0', 'B1', 'B2']})
df2 = pd.DataFrame({'A': ['A3', 'A4', 'A5'],
'B': ['B3', 'B4', 'B5']})
# 세로로 데이터프레임 이어 붙이기 (default axis=0)
result = pd.concat([df1, df2])
result

- axis : 데이터를 어느 방향으로 합칠지를 지정합니다. axis=0이면 행(row)을 기준으로 세로로 연결하고, axis=1이면 열(column)을 기준으로 가로로 연결합니다.
- ignore_index: 기본값은 False이며, True로 설정하면 기존 인덱스를 무시하고 새로운 인덱스를 생성합니다.
# 인덱스를 무시하고 연결
result = pd.concat([df1, df2], ignore_index=True)
result

ignore_index를 True로 설정하면 인덱스가 순차적으로 나오며, ignore_index를 False(기본값)로 설정하면 합치기 전의 각각의 데이터프레임의 인덱스를 보존한 상태로 인덱스가 지정됩니다.
merge 메소드
merge 메소드는 데이터프레임 간의 조인(join) 작업을 수행합니다. 두 데이터프레임 간의 공통 열 또는 인덱스를 기준으로 데이터를 결합합니다.
# 샘플 데이터프레임 생성
left = pd.DataFrame({'key': ['K0', 'K1', 'K2'],
'A': ['A0', 'A1', 'A2']})
right = pd.DataFrame({'key': ['K0', 'K2', 'K3'],
'B': ['B0', 'B2', 'B3']})# 왼쪽 데이터
left
# 오른쪽 데이터
right
# 기본 inner join
result = pd.merge(left, right, on='key')
result
- on: 어떤 열을 기준으로 데이터를 합칠 것인지를 지정합니다. 열 이름을 문자열로 전달하면 됩니다. 주로 고유한 값을 key값으로 지정합니다.
- how: 조인의 방식을 지정합니다. inner(기본값), outer, left, right 등이 있습니다.
- inner: 공통으로 존재하는 데이터만 합칩니다.
- outer: 모든 데이터를 합치고, 일치하지 않는 부분은 NaN으로 채웁니다.
- left: 왼쪽 데이터프레임의 데이터를 기준으로 합칩니다. (왼쪽 이외의 영역은 NaN)
- right: 오른쪽 데이터프레임의 데이터를 기준으로 합칩니다. (오른쪽 이외의 영역은 NaN)
# left join 예시
result = pd.merge(left, right, on='key', how='left')
result

join 메소드
join 메소드는 인덱스를 기준으로 데이터프레임을 결합할 때 사용됩니다. merge와 유사하지만, 인덱스를 기준으로 결합된다는 점이 차이점입니다.
# 샘플 데이터프레임 생성
left = pd.DataFrame({'A': ['A0', 'A1', 'A2']},
index=['K0', 'K1', 'K2'])
right = pd.DataFrame({'B': ['B0', 'B1', 'B2']},
index=['K0', 'K2', 'K3'])# 왼쪽 데이터
left
# 오른쪽 데이터
right
# 인덱스를 기준으로 join
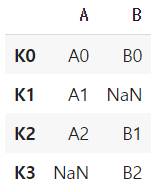
result = left.join(right)
result
기본값 inner로 인해 공통된 부분만 데이터가 join되며, 해당되지 않는 부분은 NaN(결측)처리 됩니다.
- how: 조인의 방식을 지정합니다. left, right, outer, inner(기본값) 등이 있습니다.
- on: 결합할 열을 지정할 수 있습니다. (이 경우 인덱스가 아닌 열을 기준으로 결합)
- lsuffix, rsuffix: 결합하는 데이터프레임에 동일한 이름의 열이 있을 경우 접미사를 추가하여 열 이름을 구분할 수 있습니다.
# outer join 예시
result = left.join(right, how='outer')
result
Pandas의 concat, merge, join 메소드는 각각의 데이터프레임을 어떻게 합칠지에 대한 다양한 방법을 제공합니다. 데이터프레임을 결합할 때 이들 메소드를 상황에 맞게 사용하면 효율적이고 깔끔한 데이터 처리가 가능합니다.
'파이썬을 활용한 데이터 분석 입문' 카테고리의 다른 글
| [python]데이터 전처리 - 날짜 데이터 처리하기 (0) | 2024.08.21 |
|---|---|
| [Python]데이터 전처리 - 정규화와 표준화 (0) | 2024.08.18 |
| [Python]데이터 전처리 - 문자열 처리 (0) | 2024.08.17 |
| [Python]데이터 전처리 - 중복값 처리 (0) | 2024.08.16 |
| [Python]데이터 전처리 - 파생변수 만들기 (0) | 2024.08.14 |