데이터프레임을 이용한 데이터 조작 및 분석(1) - 시리즈(Series)와 데이터프레임(DataFrame)의 차이점, 외부 데이터를 불러오는 방법
이번 시간에는 앞서 소개한 데이터 프레임을 직접 만들어보고 분석하는 방법을 소개하겠습니다. 그리고 외부 데이터를 이용하는 방법을 알아보겠습니다.
3행 4열의 데이터 프레임을 작성하였습니다.
import pandas as pd
df = pd.DataFrame({'name' : ['철수', '영희', '민지', '유진'],
'math' : [90, 70, 100, 80],
'science' : [90, 60, 70, 80]})
df이를 실행하면
name math science
0 철수 90 90
1 영희 70 60
2 민지 100 70
3 유진 80 80
다음과 같은 출력 결과를 확인할 수 있는데요, 데이터를 부분적으로 출력할 수도 있고 데이터의 평균값, 길이, 합계 등 다양한 지표를 확인할 수 있습니다.
과목 별 평균 구하기
수학 평균 점수 구하기
import pandas as pd
df = pd.DataFrame({'name' : ['철수', '영희', '민지', '유진'],
'math' : [90, 70, 100, 80],
'science' : [90, 60, 70, 80]})
df85.0
다음과 같이 데이터프레임명[’변수명’]을 통해 변수가 위치한 열이 시리즈의 형태로 모두 선택되며, 해당 시리즈(열)을 sum(series) 또는 series.sum()을 통해 합산된 결과를 구할 수 있습니다. 여기서 len(데이터프레임)을 통해 데이터의 길이를 구함으로써 과목별 합계 및 평균을 구할 수 있습니다.
여기서 시리즈(Series)란, 데이터프레임과 달리 1차원 배열과 유사한 구조를 가지며, 하나의 열(column)을 가지는 데이터구조 입니다. 두 데이터 구조의 차이점을 간략하게 알아보겠습니다.
Series (시리즈)
- 1차원 데이터 구조: Series는 일차원 배열과 유사한 데이터 구조로, 하나의 데이터 열(column)만을 포함합니다.
- 단일 데이터 타입: Series 객체 내의 모든 데이터는 동일한 데이터 타입을 가집니다 (예: 모두 정수형, 모두 문자열 등).
생성 예시
import pandas as pd
s = pd.Series([90, 70, 100, 80])
print(s)
0 90
1 70
2 100
3 80
dtype: int64
DataFrame (데이터 프레임)
- 2차원 데이터 구조: DataFrame은 표 형식의 데이터 구조로, 행과 열로 이루어져 있습니다. 여러 개의 Series가 모여서 DataFrame을 형성합니다.
- 다중 데이터 타입: 각 열(column)은 서로 다른 데이터 타입을 가질 수 있습니다 (예: 한 열은 정수형, 다른 열은 문자열형 등).
출력 예시
name math science
0 철수 90 90
1 영희 70 60
2 민지 100 70
3 유진 80 80
시리즈와 데이터프레임의 가장 큰 차이점은 시리즈에서는 변수명이 따로 주어지지 않지만 데이터프레임에서는 여러 변수값이 존재한다는 것입니다. 시리즈와 데이터프레임 모두 앞으로 용도에 따라 데이터 분석을 위해 쓰이는 데이터 구조이므로 미리 알아두는 것이 좋습니다.
외부 데이터 불러오기
다음 csv파일을 pandas를 통해 불러오는 작업을 해보겠습니다.
먼저 해당 파일을 다운로드한 후 구글 드라이브에 업로드 해야 합니다.
Google Drive → 내 드라이브 → 새폴더(Data 입력) → 해당 폴더에 업로드
다음으로 구글 드라이브를 마운트 하기 위해 다음 코드를 작성해야 합니다.
from google.colab import drive
drive.mount('/content/drive')
데이터프레임명 = pd.read_csv(’파일경로’)를 통해 불러올 수 있습니다.
파일경로는, 콜랩 화면에서 파일 → exam.csv(우클릭) → 경로복사를 통해 알 수 있습니다.
exam = pd.read_csv('파일경로')출력결과는 다음과 같습니다.
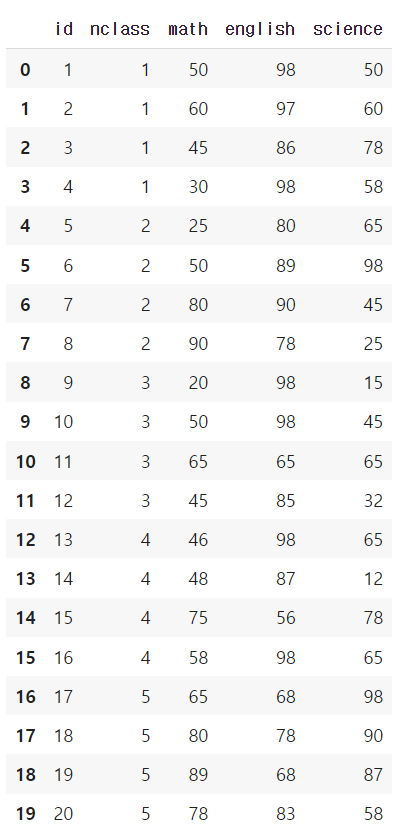
앞서 소개했던 것처럼 데이터프레임에서 일부분을 시리즈로 출력할 수 있으며, 각 변수별로 평균을 구하는 등 다양한 분석을 할 수 있습니다.
다음 포스팅에서는 데이터 구조를 파악할 때 유용한 명령어와 데이터를 분석할 수 있는 다양한 명령어를 추가적으로 계속 소개하겠습니다.